
Design of an Intelligent Agent for Email Automation Through NLP-Based Information Extraction from Arabic Text
DOI:
https://doi.org/10.51173/ijds.v3i2.61Keywords:
Natural Language Processing, NLP, Information extraction, Feature collection techniqueAbstract
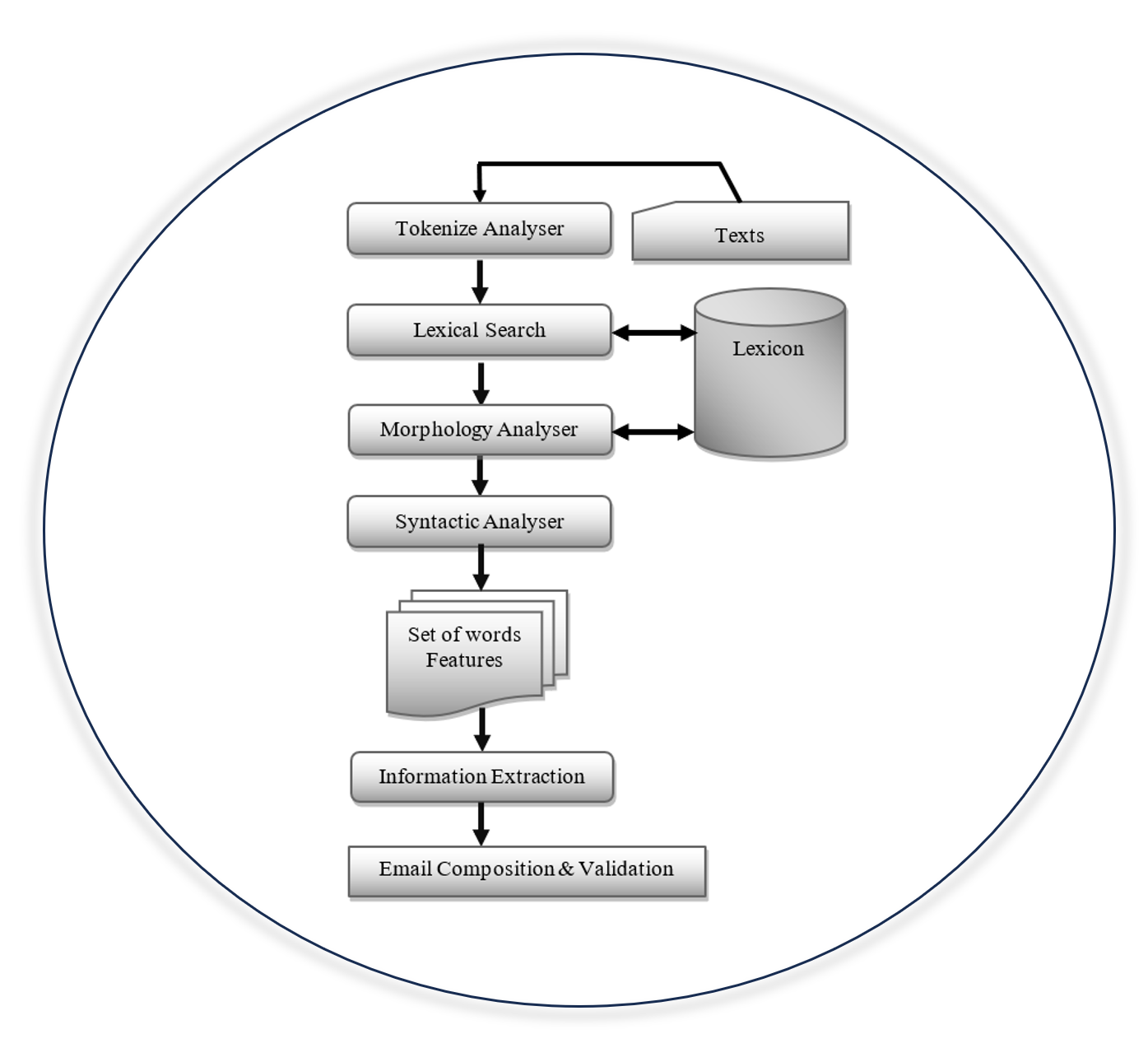
Through the tremendous results brought about by its numerous technologies in a variety of sectors, including scientific, technical, medical, and other fields, artificial intelligence has exceeded expectations and restrictions. One area of artificial intelligence called "natural language processing" has demonstrated success in a number of natural language applications, including English, Arabic, German, and other languages. Automatic Natural Language Processing is a technique used to create algorithms that mimic human labor in natural language processing, reducing time and effort required for an individual to undertake tasks necessary for that processing. The goal of information extraction is to automatically take a tailored set of data and extract it from a massive volume of input text. Many online applications depend substantially on data extraction to function. In this research, we will use Natural Language Processing (NLP) for relevant information extraction from an Arabic text and transmit it to the recipient via email. Every system or algorithm for natural language processing is assessed not only for performance, efficacy, and efficiency but also for the discovery of novel processing techniques that may be applied to the NLP domain. Three techniques are available for assessing the results: F-measure, precision, and recall. When lexical phrases are used, the information extraction methodology produces very good results; the method's extremely effective outcomes ranged from 86% to 100% with average precision as 91.4%, average recall as 90.2%, and average F-measure as 90.7%.
Downloads
References
S. Al-Azzawy and F. M. L. Al-Rufaye, "Arabic words clustering by using K-means algorithm," 2017 Annual Conference on New Trends in Information & Communications Technology Applications (NTICT), Baghdad, Iraq, 2017, pp. 263-267, doi: 10.1109/NTICT.2017.7976098.
S. Mahmood and F. M. L. Al-Rufaye, "Arabic text mining based on clustering and coreference resolution," 2017 International Conference on Current Research in Computer Science and Information Technology (ICCIT), Sulaymaniyah, Iraq, 2017, pp. 140-144, doi: 10.1109/CRCSIT.2017.7965549.
M. Rosell, "Introduction to Information Retrieval and Text Clustering," KTH CSC, Aug. 1, 2006. [Online]. Available: http://www.csc.kth.se/~magnus/ir-course/
Y.-C. Ng, "Improving Machine Learning Approaches To Noun Phrase Coreference Resolution," Ph.D. dissertation, Cornell Univ., Ithaca, NY, 2004.
S. Azzam, K. Humphreys, and R. Gaizauskas, "Coreference Resolution in a Multilingual Information Extraction System," Dept. of Computer Science, Univ. of Sheffield, Sheffield, UK, 1998.
A. Nenkova and K. McKeown, "Automatic Summarization," Foundations and Trends in Information Retrieval, vol. 5, no. 2–3, pp. 103–233, 2011. doi: 10.1561/1500000015
R. Radev, E. Hovy, and K. McKeown, "Introduction to the Special Issue on Summarization," Computational Linguistics, vol. 28, no. 4, pp. 339–400, 2002. doi: 10.1162/089120102762671927
H. F. Khelil, M. F. Ibrahim, H. A. Hussein, and R. K. Naser, "Evaluation of Different Stemming Techniques on Arabic Customer Reviews," Journal of Techniques, vol. 6, no. 2, pp. 1–8, 2024. doi: 10.51173/jt.v6i2.2313.
A. A. Alsuwaylimi, "Enhancing Arabic Phishing Email Detection: A Hybrid Machine Learning Based on Genetic Algorithm Feature Selection," Int. J. Adv. Comput. Sci. Appl., vol. 15, no. 8, pp. 312–325, 2024. doi: 10.14569/IJACSA.2024.0150833
Masri and M. Al-Jabi, "A novel approach for Arabic business email classification based on deep learning machines," PeerJ Comput. Sci., vol. 9, e1221, 2023. doi: 10.7717/peerj-cs.1221
H. Tarek and A. Daud, "Intelligent Agent for Information Extraction from Arabic Text without Machine Translation," 2010.
Zakria, M. Farouk, K. Fathy, and M. N. Makar, "Semantic Representation Extraction from Unstructured Arabic Text," in Proc. 2019 8th Int. Conf. Software and Information Engineering (ICSIE '19), New York, NY, USA: ACM, 2019, pp. 222–226. doi: 10.1145/3343023.3343046
Hkiri et al., "Events Automatic Extraction from Arabic Texts," in Natural Language Processing: Concepts, Methodologies, Tools, and Applications, IGI Global, 2020, pp. 1686–1704. doi: 10.4018/978-1-7998-1502-6.ch082
S. Mohamed, M. Hussein, and H. Mousa, "Arabic open information extraction system using dependency parsing," Int. J. Electr. Comput. Eng., vol. 12, no. 1, pp. 541–551, 2022. doi: 10.11591/ijece.v12i1.pp541-551
S. Aung, C. T. Zan, and H. Yamana, "A Survey of URL-based phishing detection," in Proc. DEIM Forum, 2019, pp. 2–3.
M. R. D. Silva, E. L. Feitosa, and V. C. Garcia, "Heuristic-based strategy for phishing prediction: A survey of URL-based approach," Comput. Secur., vol. 88, Jan. 2020, doi: 10.1016/j.cose.2019.101628
T. Sharma, "Evolving Phishing Email Prevention Techniques: A Survey to Pin Down Effective Phishing Study Design Concepts," 2021. [Online]. Available: http://hdl.handle.net/2142/109179.
A. Mukherjee, N. Agarwal, and S. Gupta, "A survey on automatic phishing email detection using natural language processing techniques," Int. Res. J. Eng. Technol., vol. 6, no. 11, pp. 1881–1886, 2019.
Khurana, A. Koli, K. Khatter et al., "Natural language processing: state of the art, current trends and challenges," Multimed. Tools Appl., vol. 82, pp. 3713–3744, 2023. doi: 10.1007/s11042-022-14547-6
S. Salloum, T. M. A. Gaber, S. Vadera, and K. Shaalan, "A systematic literature review on phishing email detection using natural language processing techniques," IEEE Access, vol. 10, pp. 65703–65727, 2022. doi: 10.1109/ACCESS.2022.3184355
Barbu and R. Mitkov, "Evaluation tool for rule-based anaphora resolution methods," School of Humanities, Languages and Social Sciences, Univ. of Wolverhampton, UK.
Downloads
Published
How to Cite
Issue
Section












